Where coverage chaos usually starts
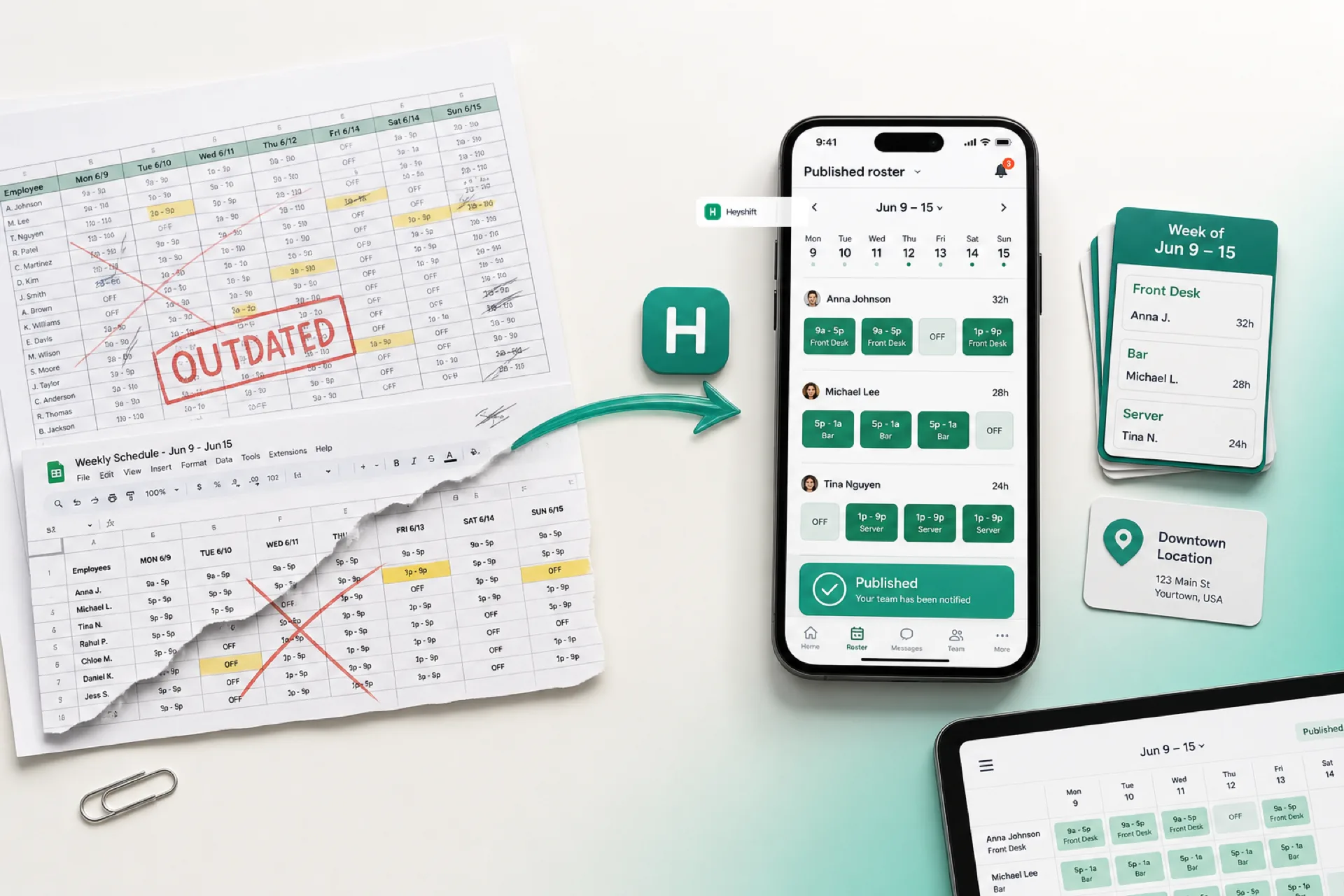
Operators rarely lose the week because nobody cares. They lose it because two versions of the schedule exist at once: what got published, and what managers patched in chat or side files after callouts.
That gap shows up as:
- Crews showing up to shifts that “changed” without a thread they trust.
- Payroll chasing screenshots instead of an approvals trail.
- Site leads negotiating swaps privately, then hoping someone updates the official grid.
The fix is not “more discipline.” It is a workflow where open shifts and swaps route through the same door as publish, so exceptions stay visible instead of forked.
Route exceptions through scheduling software that keeps swaps on the published roster.
For a broader guide on employee shift swapping policy, labor checks, and growing-team habits, see shift swapping best practices for growing teams.
Define what “open shift” means before you post it
Consistency beats clever policy. Before you lean on open postings mid-week, agree on basics every location repeats:
- Which roles can post opens versus only claim them.
- Whether claiming is first-come or manager-approved for certain grades or minors rules.
- How long an open sits visible before escalation (so nobody discovers a hole during handoff).
Small clarifications prevent the worst failure mode: an open shift that “felt handled” in a group message but never landed where finance and compliance can see it.
Swap approvals should answer three questions fast
When someone asks to trade shifts after publish, supervisors are really deciding:
- Coverage: Does the swap keep skills and ratios honest for that window?
- Policy: Does it conflict with breaks, weekly caps, or training requirements you track?
- Proof: Can you explain the decision next Tuesday without reconstructing DMs?
Teams that win treat swaps like tiny contracts: requested, reviewed, approved or declined in one system, then reflected on the roster everyone already opened on mobile.
Spreadsheets can store the outcome. They rarely store the why under pressure.
Publish-first scheduling is the guardrail, not the bureaucracy
Publish-first does not mean “no changes after Wednesday.” It means changes flow through visibility:
- Managers see pending swaps next to the live grid instead of buried in notifications.
- Employees stop debating whether the PDF or the app is current, because publish stays the anchor.
- Ops can spot patterns (repeat requesters, chronic gaps at handoff) instead of firefighting case by case.
If your tool makes posting opens easy but hides approvals, you will get speed today and disputes tomorrow. Balance matters.
Multi-site teams need one vocabulary for exceptions
When you run several locations, approvals break when every GM names regions differently or uses separate swap rituals.
Standard language helps:
- Same labels for areas or stations when swaps reference coverage.
- Same escalation path when nobody picks up an open shift by cutoff.
- Same audit expectation: who approved, when, and against which published version.
Rollout is smoother when “how we handle swaps here” matches “how we handle swaps there,” even if volumes differ.
Operational checklist you can reuse weekly
- Post opens inside the scheduling workflow; ban parallel “who can cover?” threads for roles that must be tracked.
- Require manager approval for swaps that touch premium windows (weekends, holidays, inspections).
- Review a short report of pending versus approved swaps before payroll export, not as punishment, as insurance.
- Retrain crews once a quarter on where to look for the real roster after publish.
Small habits compound into fewer no-shows and cleaner answers when labor asks what changed. For a broader attendance playbook, see how to reduce employee no-shows and last-minute call-offs.
How Heyshift fits this pattern
Heyshift is built around publish-first scheduling for USA teams that cannot afford forked truth across sites: shift scheduling, mobile app visibility, and manager approvals so crews align on what actually shipped, not what circulated in chat.
If open shifts and swaps are where your week unwinds, tighten that loop first. Everything else, from forecasting to templates and rollout, gets easier when exceptions stop inventing shadow books.
Book a demo or start a Free trial to map open-shift rules and approval seats on your published roster.